Find best hyperparameters using Grid Search in SVM (Support Vector Machine)
The hyperparameters optimization is a big part now a days in
machine learning.
In this post, we’ll use the grid search capability from the
sklearn library to find the best parameters for SVM. We’ll be using wine
dataset for this post(Link). Here, I have divided the
whole dataset as train and test data randomly.
Grid search is the hyperparameter optimization technique. It
is provided as GridSeachCV in sklearn.


Let’s start with importing packages and loading the data.
from sklearn.model_selection import train_test_split
from sklearn import svm
import numpy as np
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import GridSearchCV
# loading the data
wine_train = np.loadtxt('wine.train',delimiter=',')
wine_test = np.loadtxt('wine.test',delimiter=',')
x = wine_train[:, 1:13]
y = wine_train[:, 0]
X_Test = wine_test[:, 1:13]
x_train, x_test, y_train, y_test = train_test_split(x,y)
Now, we will define the range for parameters through which Grid
Search will try to find optimized parameters.
We’ll be passing these parameters as a dictionary to the GridSearchCV
and we’ll also specify the cross-validation. In our case it is a Stratified ShuffleSplit
Cross-validator.
# finding best parameter for SVM
C_range = np.logspace(-2, 10, 13)
gamma_range = np.logspace(-9, 3, 13)
param_grid = dict(gamma=gamma_range, C=C_range)
#cross validation for SVM
cv_SVM = StratifiedShuffleSplit(n_splits=15, test_size=0.2, random_state=0)
grid_SVM = GridSearchCV(svm.SVC(kernel='linear'), param_grid=param_grid, cv=cv_SVM)
grid_SVM.fit(x_train, y_train)
print("The best parameters for SVM are %s" % (grid_SVM.best_params_))
We got the optimized parameters. Now, let’s train our model
for SVM (Support Vector Machine).
c = grid_SVM.best_params_['C']
gamma = grid_SVM.best_params_['gamma']
model_SVM = svm.SVC(kernel='linear', C=c, gamma=gamma)
model_SVM.fit(x_train, y_train)
y_predicted_SVM = model_SVM.predict(x_test)
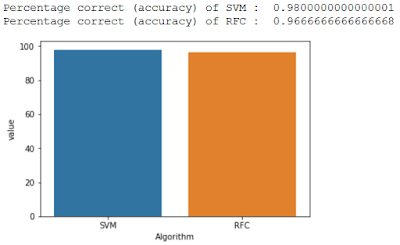
SVM_Accuracy = np.mean(y_test == y_predicted_SVM) * 100
print('Percentage correct (accuracy) of SVM : ', np.mean(y_test == y_predicted_SVM))


Comments
Post a Comment