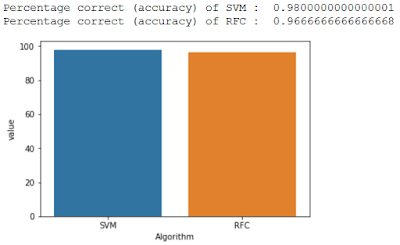
Apriori algorithm implementation in R
Introduction
it is an algorithm for frequent itemset mining and association rule learning over transactional databases. It proceeds by identifying the frequent individual items in the database and extending them to larger and larger item sets as long as those itemsets appear sufficiently often in the database. The frequent itemsets determined by Apriori can be used to determine association rules which highlight general trends in the database, this has applications in domains such as market basket analysis.
This post is about the implementation of the apriori algorithm in R not to the detailed explanation of it.
First, Download and install R Studio from link if it is not installed in your system.
1. First, install the required packages named - arules and apriori.
Go to Tools -> Install Packages --> arules/apriori
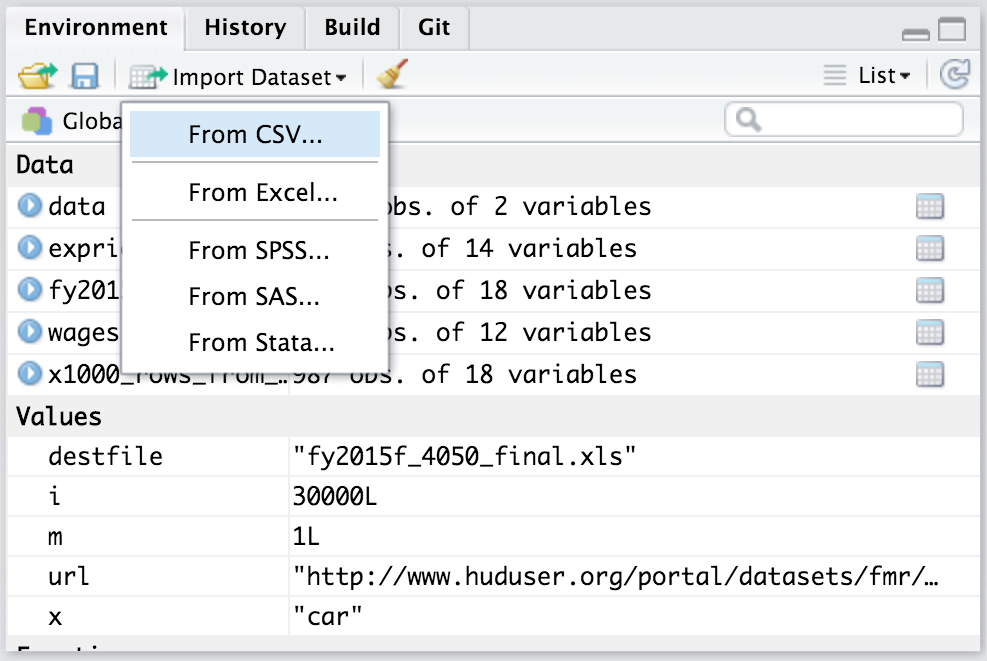
2. Importing your data set
The data import features can be accessed from the environment pane or from the file menu. The importers are grouped into 3 categories: Delimited data, Excel data and statistical data. To access this feature, use the "Import Dataset" dropdown from the "Environment" pane:
Here, my sample data is as shown in the below image. it is about various weather condition against the possibility to play tennis.

3. Now we will import arules and apriori and set support and confidence values (in our case it is 30% and 50% respectively) against the imported dataset to generate the rules. once we have generated it we will inspect it to get better insight.
# reading CSV File
X2 <- read.csv("1.csv")
# Importing library
library(arules)
# training classifier, providing min support and confidence
rules <- apriori(X2,parameter = list(supp = 0.3, conf = 0.5, target = "rules"))
# generating summary of the rules
summary(rules)
# inspecting the generated rules
inspect(rules)
Now if we want to measure the execution time and save the generated rules to the file. find the whole code for the implementation below.
# starting timer
startTime <- proc.time()
# reading CSV File
X2 <- read.csv("1.csv")
# Importing library
library(arules)
# training classifier, providing min support and confidence
rules <- apriori(X2,parameter = list(supp = 0.3, conf = 0.5, target = "rules"))
# generating summary of the rules
summary(rules)
# inspecting the generated rules
inspect(rules)
# showing consumed time
proc.time() - startTime
# saving rules in csv file
write(rules, file = "output.csv", sep = ",", quote = TRUE, row.names = FALSE)
Result


Subscribe my blog for the further technical guide. Cheers!